Drop us a line
If you are interested in the development of a custom solution — send us the message and we'll schedule a talk about it.
Custom system for engineering drawings digitization powered by artificial intelligence to extract data from on-paper maps, schemes, and other technical documents.
Together with our Strategic partner DIGATEX, we combined our software and data science skills and their domain knowledge of engineering data management to create DI-analytics, a unique solution to digitising vast amounts of advanced documents for customers who own and operate complex assets such as oil refineries and offshore production facilities.
One of the first customers for this solution is a South East Asia corporation that explores and manufactures petrochemical products. The company is ranked among Fortune Global 500’s largest corporations in the world with business interests spanning 35 countries.
Due to specific business demands the customer regularly has to digitise vast amounts of advanced documents. The service was provided as an outsourced process comprising document processing, data extraction and collation.
The number of documents was increasing faster than the vendor can digitize.
Extracting such data accurately using conventional methods is very costly.
The objective was to build a solution for digitizing a large number of complex documents in the shortest terms. The majority of documents were pipeline layouts, industrial plans, manufacturing schemes and maps obtained from the third-party vendors and partners.
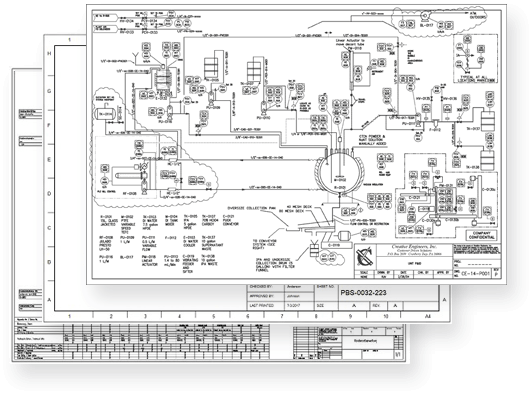
All documents from a single vendor or partner can be divided into several groups, and each group has multiple document templates. So, hundreds of vendors lead to the thousands of templates.
It is very challenging for a human not only to remember all the templates but also to determine the right template that suits the specific document. The first concern we faced was to determine the document template, to know what kind of data to extract.
Another challenge was to extract the data from the technical documents. Every template has it is own unique set of fields, custom abbreviations and unique symbols in addition to the flexible structure.
Our goal was to make the application to determine the zones and fields of the document automatically, without manual mapping. It is a very challenging process if we take into consideration the number of various templates.
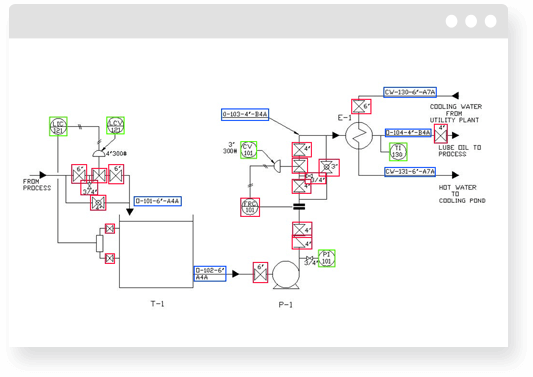
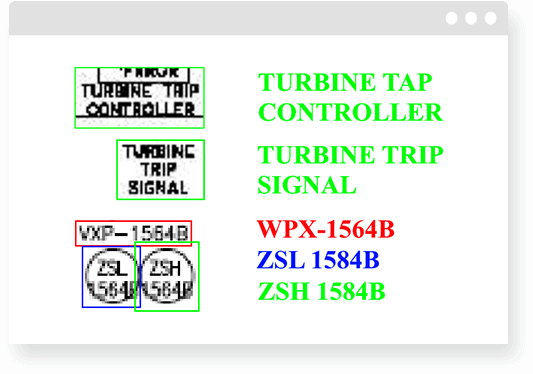
The majority of schemes and plans were autogenerated by other software applications in multiple steps. It was the usual situation when the information we need to extract lies under another element or abbreviation. It is challenging even for the human to read some schemes.
Our engineers decided to train the machine learning to recognize complicated elements according to its previous experience and already extracted data.
After initial research, we figured out – no existing technology can help us to overcome the customer challenges. Several companies provide similar services, but their products are entirely unsuitable for the documents with flexible structure and industrial maps.
AI was a good option – it acts like a human, and it uses the same algorithms and methods while searching the data patterns in the document as the human does.
The solid scientific background helped our engineers to build MVP in less than two weeks. We immediately requested the first documents from the customer and got a predictable result, that impressed the customer.
Since that moment, we have been tuning algorithms and improving the performance of the system.
The final application is the entirely modular system, hosted in the secure enterprise cloud. Allon-going tuning and maintenance are entirely remote, what helps the customer to avoid on-site personnel training and cut down maintenance costs.
We are proud to say, that a small group of neural networks powers every single module, and all the modules form a unique artificial intelligence that takes the document as the input, and provides the accurately extracted data as the output.
As the artificial intelligence is hosted in the cloud, it can be easily managed from any place. If the customer wants to process a considerable number of documents in the shortest terms, we can enable the required resources in several minutes and handle any number of documents.
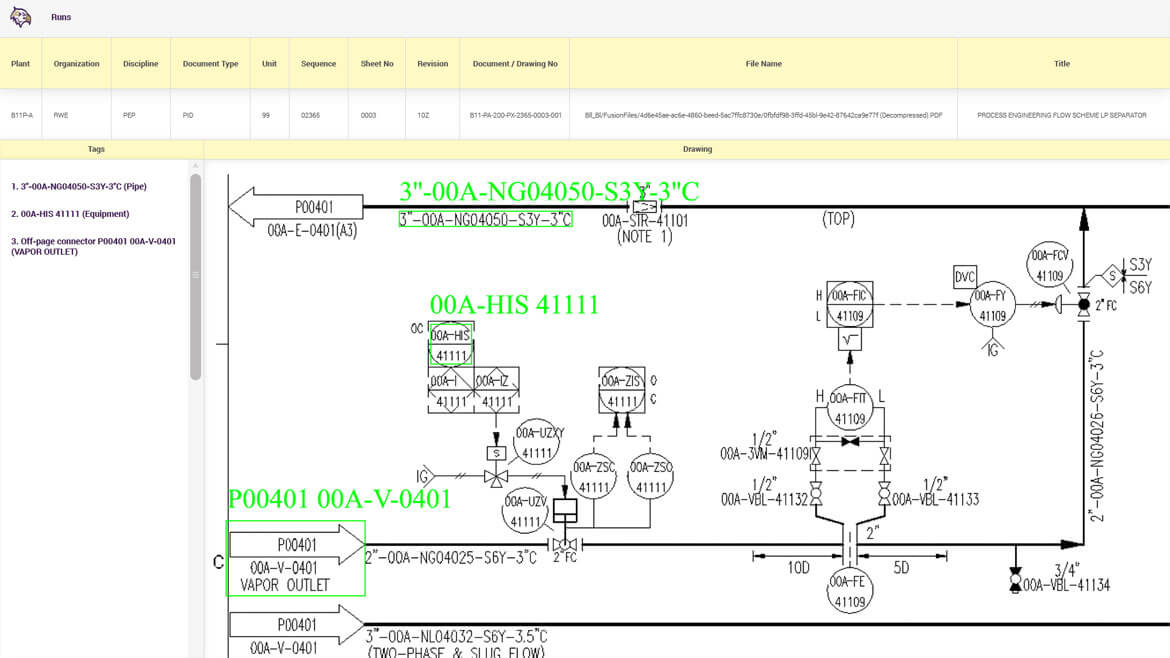
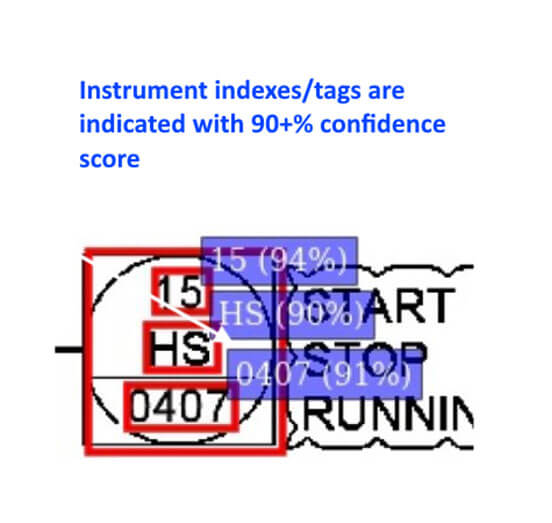
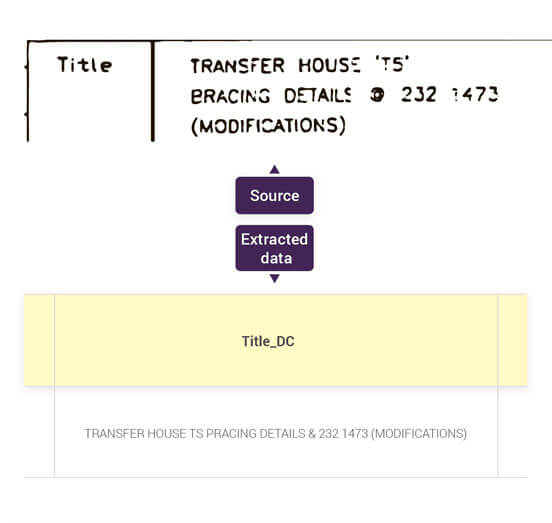
We are the first who successfully implemented computer vision (CV) technologies to power a little artificial intelligence to process a large number of documents with flexible structure and custom abbreviations.
Our engineers developed custom artificial intelligence that determines the template of the document, accurately extracts data, links and maps the data into the complete datasets.
And freed 30 people from doing routine work.
We made it possible to extract data from documents with flexible struture.
The project took 6 weeks when customer planned 6 months.
At this moment DIGATEX and Azati are maintaining this system as a service. The primary focus istuning the data extractions algorithms, training neural networks to extract the data accurately and fast.
If you are interested in the development of a custom solution — send us the message and we'll schedule a talk about it.
JavaScript, Ruby
HR Planning SoftwareThe customer asked Azati to audit the existing solution in terms of general performance to create a roadmap of future improvements. Our team also increased application performance and delivered several new features.
Python
Stock Market Trend Discovery with Machine LearningAt Azati Labs, our engineers developed an AI-powered prototype of a tool that can spot a stock market trend. Online trading applications may use this information to calculate the actual stock market price change.
Python
Semantic Search Engine for Bioinformatics CompanyAzati designed and developed a semantic search engine powered by machine learning. It extracts the actual meaning from the search query and looks for the most relevant results across huge scientific datasets.
Java, JavaScript
E-health Web Portal for International Software IntegratorAzati helped a well-known software integrator to eliminate legacy code, rebuild a complex web application, and fix the majority of mission-critical bugs.
JavaScript, Ruby
Custom Platform for Logistics and Goods TransportationAzati helped a European startup to create a custom logistics platform. It helps shippers to track goods in a real-time, as well as guarantees that the buyer will receive the product in a perfect condition.
