All technologies used






Motivation
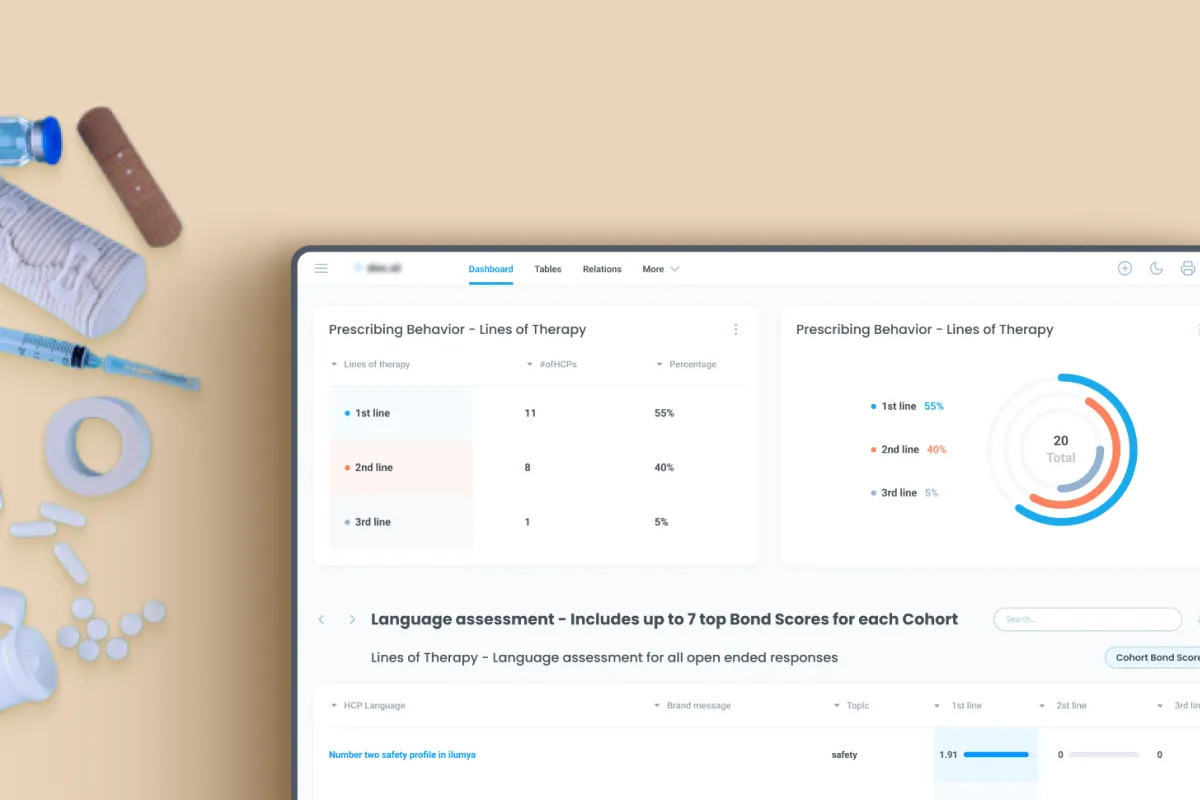
To develop an intelligent semantic search engine that addresses the inefficiency and inaccuracy of the client’s existing system, eliminating the need for manual tag selection, handling inconsistent descriptions, synonyms, and variations in blood sample data, significantly speeding up search queries from minutes to milliseconds, and providing a scalable solution capable of adapting to new datasets while ensuring relevant results are consistently found.
Main challenges
Blood sample descriptions and manually assigned tags were inconsistent, leading to inaccurate search results. Azati addressed this by cleansing and standardizing the data, training a custom Word2Vec model to understand synonyms and relationships between terms, ensuring the search engine could correctly interpret and match queries despite inconsistencies.
The team faced challenges due to multiple naming conventions and variations in disease names, which hindered precise tagging and search accuracy. Azati solved this by analyzing hundreds of thousands of life sciences documents to build a comprehensive thesaurus and train the Word2Vec model to detect and map synonyms, enabling accurate semantic matching.
The project involved processing a vast number of entries without any pre-labeled sample data for algorithm training. Azati overcame this by leveraging open-source life sciences documents to create a training dataset, developing intelligent matching and query analysis modules, and implementing RESTful microservices with Redis caching for efficient, scalable search performance.
Our approach
Facing the same challenge?
Bring your complexity. We'll bring the plan. Select a convenient slot to start a conversation with our experts.
Schedule a callSolution
Intelligent Matching Module
- Automatic tagging of blood samples
- High-confidence semantic matching (~98%)
- Handling inconsistent or incomplete data
- Custom Word2Vec model trained on life sciences documents
Query Analysis Module
- Natural language processing for query analysis
- Entity extraction (sample type, disease, geography, etc.)
- Conversion of unstructured queries into structured data
- Improved search precision and recall
RESTful Microservices Architecture
- Scalable cloud deployment
- Independent module updates and maintenance
- Integration with existing infrastructure
- Flexible expansion for new datasets or modules
Performance Optimization with Redis
- In-memory caching with Redis
- Sub-30 millisecond query response
- High-throughput data processing
- Efficient handling of large scientific datasets
Business Value
High Accuracy Tagging: Enabled automatic analysis and tagging of blood samples with up to 98% confidence, reducing manual effort and errors.
Blazing Fast Query Response: Search queries return results in ~27 milliseconds, improving employee productivity and satisfaction.
Scalable Neural Network Retraining: New datasets can be incorporated in ~3 minutes, allowing the system to adapt quickly to expanding scientific data.
Improved Search Precision: Semantic matching of queries to datasets significantly reduced irrelevant results and enhanced data accessibility for researchers.