All Technologies Used










Motivation
The project aimed to process massive volumes of unstructured patent and biological sequence data while ensuring high-quality metadata, scalable processing, efficient retrieval, compliance with global IP standards, and automation of labor-intensive workflows. It focused on enabling actionable insights, faster discovery, and improved efficiency for researchers and IP analysts.
Main Challenges
Patent documents and biological sequences were in multiple formats (PDF, XML, FASTA, GenBank) and updated continuously. Processing terabyte- to petabyte-scale datasets required large-scale ingestion, normalization, cleaning, and indexing pipelines capable of handling diverse and unstructured data.
Many records lacked standardized metadata, hindering search, classification, and contextual understanding. Relationships between sequences, annotations, and patent claims were often lost during manual processing, reducing analytical value and complicating compliance and reproducibility.
Annotation, summarization, and monitoring were labor-intensive, error-prone, and difficult to scale. Researchers spent significant time curating data, tracking updates, and maintaining quality control, limiting overall operational efficiency.
The client required a modular AI system capable of automating metadata enrichment, semantic search, intelligent summarization, and workflow automation. The solution had to integrate with existing pipelines, support cloud and on-premises deployment, and be flexible for future AI-driven capabilities.
Our Approach
Want a similar solution?
Just tell us about your project and we'll get back to you with a free consultation.
Schedule a callSolution
AI-Powered Data Ingestion & Normalization Module
- Multi-format document & sequence ingestion
- Automated normalization, cleaning, and deduplication
- Scalable indexing pipelines for terabyte–petabyte datasets
AI Metadata Enrichment & Context Recognition Module
- AI-based metadata generation & standardization
- Context and relationship extraction
- Compliance-ready structured data output
Semantic Search & Discovery Module
- Semantic, hybrid, and vector similarity search
- Domain-specific embeddings for patents & sequences
- Intelligent exploration and filtering of large datasets
AI-Assisted Summaries, Annotation & Insights Module
- AI-driven patent and sequence summarization
- Automatic annotation & insight generation
- Interactive AI assistant for researchers and IP analysts
Business Value
Massive Data Processing: The platform successfully processed over 50 million patent documents and biological sequences, enabling scalable analysis of terabyte- to petabyte-scale datasets.
Reduction in Manual Work: Automated annotation, summarization, and metadata enrichment reduced manual effort by 72%, freeing researchers and IP analysts to focus on higher-value tasks.
Enhanced Search Accuracy: AI-driven semantic search and enriched metadata improved search accuracy and result relevance to 91%, enabling faster discovery of patents and sequence similarities.
Accelerated Research Workflows: AI-generated summaries and automated insights significantly reduced the time required for patent analysis and sequence interpretation, accelerating scientific research and IP evaluation.
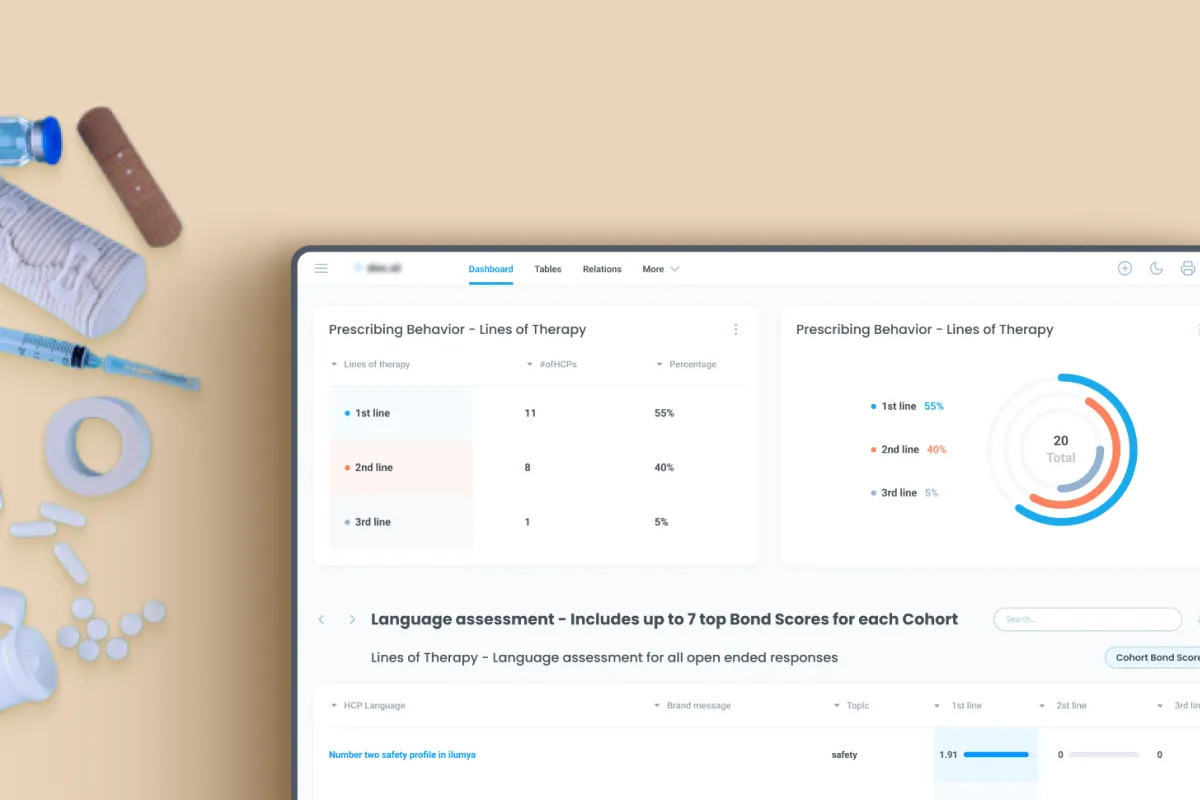
Operational Transparency: Real-time dashboards and performance monitoring provided administrators with complete visibility into data volumes, workflow progress, and system performance, ensuring stability during large-scale processing.
Actionable Insights: Researchers and IP analysts gained structured, interpretable data with AI-enriched annotations and contextual relationships, enabling faster decision-making and more accurate IP analysis.