Improved Short-Sequence Accuracy
Researchers gained access to significantly more relevant matches, even for very short sequences.
Azati optimized the BLAST algorithm to improve accuracy when working with short DNA/RNA sequences, enabling a biotechnology company to conduct more reliable primer-based research and improve the effectiveness of their genomic sequence analysis.
more relevant matches retrieved for short (<20 bp) sequences
reduction in false negatives in primer-based searches
faster end-to-end sequence analysis workflow due to automation


A biotechnology corporation approached Azati after struggling to obtain meaningful results when running short DNA/RNA sequences (primers under 20 bases) through the BLAST algorithm. Their researchers repeatedly encountered missing matches and incomplete alignments, slowing down genomic analysis and preventing accurate primer-based studies, critical for advancing personalized medicine research. The client needed a more sensitive, reliable, and automated BLAST configuration capable of extracting relevant hits from short sequences without requiring manual parameter tuning.
Researchers working with short primer sequences were not getting sufficient matches from the BLAST algorithm, as it missed significant alignments due to strict default parameters. Azati proposed customizing the algorithm to adjust its sensitivity and thresholds, ensuring better results for short queries.
The default configuration of BLAST prioritized longer sequences, which severely limited its effectiveness for specialized short-sequence research. Azati addressed this by redesigning the system to support dynamic parameter tuning based on input length.
Short sequences created a heavy risk of false negatives due to BLAST’s probability-driven scoring model. Many biologically meaningful partial matches simply never surfaced. The team needed enhanced filtering and sensitivity tuning to surface these hidden alignments without cluttering results with noise.
Analyzed the client’s use case focused on primer matching and identified the limitations of the default BLAST settings for short sequences.
Customized BLAST algorithm parameters, lowering the significance threshold and adjusting sequence length filters to increase sensitivity for queries under 20 bases.
Implemented dynamic system behavior to auto-adjust these values on the search page, ensuring consistent performance without requiring user intervention.
Integrated additional filters into the algorithm logic to refine search accuracy and reduce false negatives.
Modified the core BLAST codebase to embed the optimizations into the system, making it scalable and robust for long-term research use.
Bring your complexity. We'll bring the plan. Select a convenient slot to start a conversation with our experts.
Schedule a callA custom optimization layer enhances BLAST accuracy for DNA/RNA fragments under 20 bases. It recalibrates default scoring, adjusts seed lengths, and ensures that short primers, typically ignored by standard BLAST, produce biologically meaningful results.
A dynamic adjustment system automatically tunes BLAST parameters based on the characteristics of the query sequence, eliminating the need for manual setup and ensuring consistent accuracy across varying input lengths.
Custom filters refine search results by reducing false negatives without inflating irrelevant noise. This ensures high-value matches surface even in complex genomic datasets.
Researchers gained access to significantly more relevant matches, even for very short sequences.
Eliminated the need for manual reconfiguration, enabling faster, more intuitive search operations.
Empowered the client to conduct higher quality genetic studies, especially in therapeutic discovery and personalized medicine.

AI platform transforming patent and sequence data into actionable insights with advanced AI modules.

AI-powered calorie counting app estimating dish calories through image analysis.
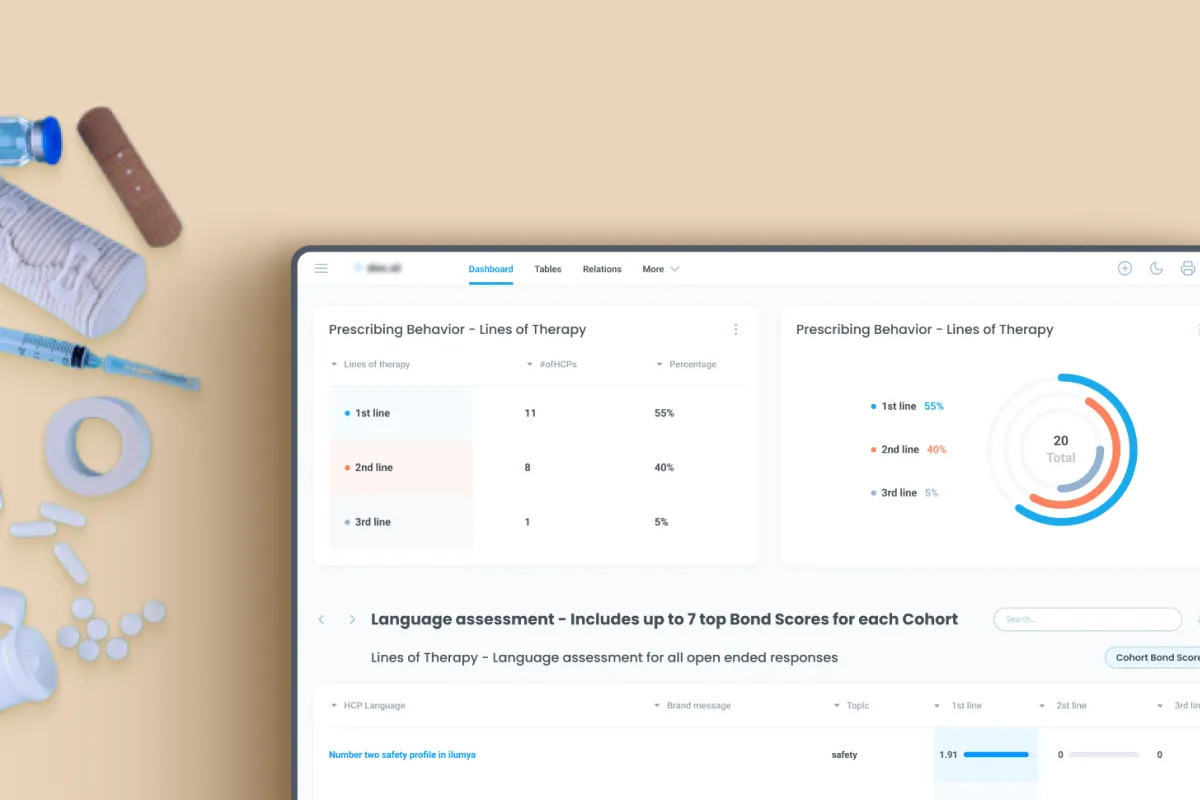
AI and Computer Vision solution for automated pharmaceutical marketing assessment reports.
Merged healthcare solutions with enhanced UI and optimized business processes.

Online data source for sequence information and IP search needs.

ML-powered semantic search engine for complex scientific datasets.
Last updated